FESSEX Consulting can help you accelerate or build from the ground up your “Big Data Infrastructure”, including all your data collection, Data Lake, cleans/results layer; A through Z, we will build your Data Pipeline; furthermore, once the pipeline is in place, we can work with you on what comes next, making your data actionable.
As part of building your entire (or partial) Data Pipeline, we will insure that you remain compliant with Privacy legislation (California CCPA and other US states/EU GDPR/China PIPL/Canada/India/Japan/UEA) around the world. Furthermore, we are obsessed with security and as such, our approach in any infrastructure work is security first.
One misconception that we normally have to address is the discussion between Data Lakes and Data Warehouses. They are not interchangeable. The following is a discussion that helps clarify the differences between both of them and the benefits of using Data Lakes over Data Warehouses.
Contact us today & Get a FREE Discovery Call! Start Here

Using Data Lakes and Experimental Data Science to Accelerate Answering Questions
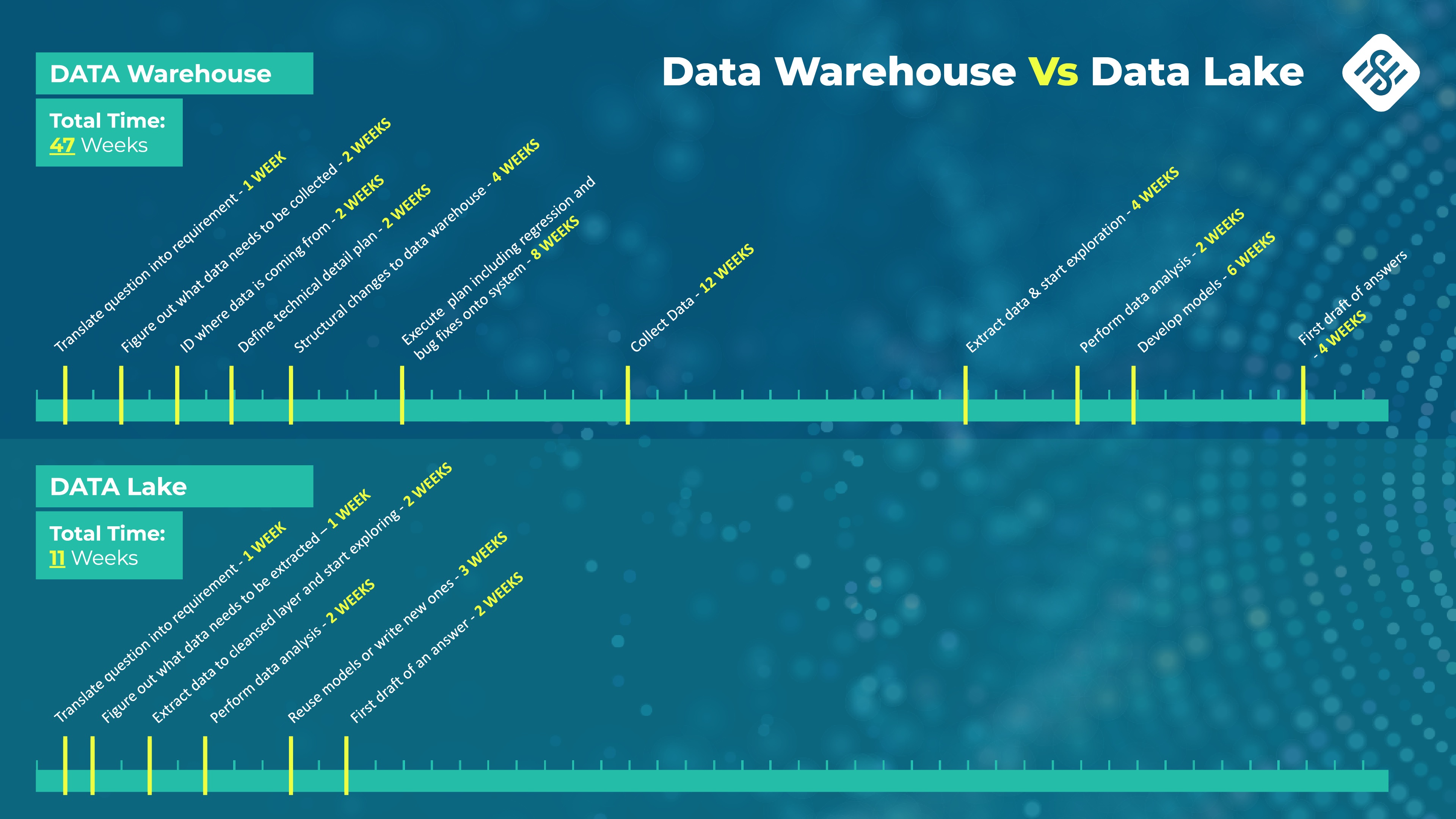
Traditionally, companies have organized their data in data warehouses. Decisions had to be made as to what data to collect and organize and what data to ignore and lose, potentially forever. This schema presents a problem in that not all questions can be answered expediently; in particular, market-driven and strategic questions since NOT ALL DATA is kept.
Let’s look at a potential use case:
Data Warehouse
Est. time to conclusion: 47 Weeks
The organization’s CEO or CFO have a particular question; for the sake of this use case, let’s assume the data was not collected.
The following timeline will play out in order to answer the questions:
It will take a minimum of 47 weeks, to answer a question where market timing is paramount.
After 47 weeks, the question is no longer relevant.
Data Lake
Est. time to conclusion: 11 Weeks
Before we look onto what it takes to answer the question using modern methodologies, let’s understand what a data lake is:
What is a Data Lake?
Data Lakes are data stores where there is a raw and a cleansed or curated component. The raw component contains all data generated by a system, whether it will be used or not. Storage is inexpensive and the implications of not keeping data are far riskier than the storage cost. The cleansed or curated layer is the needed subset of data that is extracted from the raw layer and is the data needed “right now”. Visualization tools use this layer to create dashboards and produce reports.
The advantage of keeping all data in the raw layer is that when needed the data is there to be curated. Moreover, there is no need to “improve” the data collection infrastructure.
Let’s look at the same use case using a data lake and experimental data science:
This takes only 11 weeks to answer the same question.
A few areas to note:
- No need to wait for data to be collected because it is always fully collected
- Data exploration and analysis are two tasks that are constantly going on under this model; adding new and/or more data and refocusing is also a constant
- Modifying existing models or even creating new models is accelerated because they are constantly needed for data exploration
- Tools are already in place and in constant use