

Business Problem
We were hired by a customer to execute a project that included several advanced analytics and experimentation tasks: churn models, predictive LTV, segmentation and A/B testing, among others.
However, it became clear very soon that this client didn’t have the data infrastructure needed to support these efforts. In fact, they didn’t even have the basic reporting capabilities needed for their normal operations, they were stuck with their data siloed among several vendors after a fairly traumatic migration
After a discovery process, we were commissioned to build a cloud data lake from scratch, in order to consolidate the multiple data sources available and create a centralized and consistent source of truth for analytics and operational purposes.
Starting point
After a careful analysis we outlined some design principles for this data lake:
- It should be 100% cloud hosted (our client uses AWS)
- It should be scalable and flexible: new data sources could be added after implementation and existing data sources could grow significantly in volume without major architecture changes
- A portion of the data, which was critical, should be available in production in few weeks, with other data sources taking a bit longer
- It should be easy to maintain, well organized and documented
Architecture
Based on the premises described in the previous section, we designed a layered architecture as shown below:
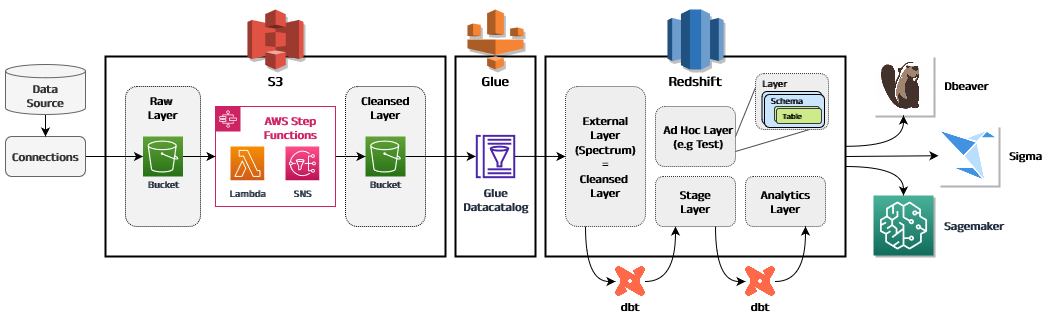
The data from all sources is ingested into the raw layer via different methods, including API calls with Lambda functions, SFTP dumps, direct S3 dumps, and manual ingestion (depending on the data source nature). The raw layer is hosted in S3 buckets and the files are maintained unchanged, without any transformation.
The data in the raw layer is processed using a combination of Lambda and Step Functions to transform it into tabular format and store it in the cleansed layer. This layer is hosted in S3 and consists of mostly parquet files organized in partitions and registered in Glue catalog.
The final section of the data lake is the Redshift cluster. The aforementioned cleansed layer can be read from Redshift using Spectrum, a technology that takes advantage of the Glue catalog and allows querying those files as external tables. These tables (located in S3 but readable from Redshift) constitute the external layer.
Downstream, we read the data and apply additional transformations, storing it as internal schema/tables/views in the stage layer which contains intermediate tables necessary for further processing, or in the analytics layer that contains the final data ready for consumption by business stakeholders. Additionally an Ad Hoc layer was incorporated for data that doesn’t fit on previous layers.
Data Ingestion
One of the most challenging parts of the project was to ingest data sources into the centralized repository.
It wasn’t difficult because they were technically challenging, quite the contrary. The difficulty lies in the amount of sources and their heterogeneity. For this project we had to ingest more than 15 data sources, some of which were from internal systems, both current and legacy. Some of them were from third party vendors.
For each of them we had to follow certain steps. First, we had to navigate the corporate structure to find the person who could give us access to the data, sometimes this person belonged to a 3rd party organization or a vendor. After that we had to explore the data, figure out the transmission mechanism (API, SFTP, S3 dumps, manual uploads) and determine, in collaboration with the client, which data was worth ingesting. Only after this was clear, could we start with the engineering tasks of building the pipeline and data transformations.
Data Transformations
Once the data is clean and standardized in the external layers, many transformations are needed to generate the tables that the user will consume. Some transformations are simple, like changing the timezone from a column or parsing some data from a text field. Other transformations are more complex and include aggregations, calculations, incorporation of business logic, and combinations of data from different tables.
In order to keep all data transformations orchestrated and traceable, we relied on dbt, an open source tool that is proven instrumental in many modern data stacks across different companies and industries.
Some of the advantages of using dbt:
- Version control for data transformations
- Easy to keep separate test and production environments, so the data transformations can be checked before pushing to production
- It empowers data analysts to write the transformations they need, taking the heavy lifting out of the data engineer and drastically reducing the time from concept to production
- It keeps track of dependencies between queries
- It allows for easy scheduling and orchestration of the processes
- It has a powerful testing feature for data quality assessment
Exploitation
The most important part of any data lake project is its ability to deliver value to the business. Having the information from all company systems concentrated in a single source of truth is a great competitive advantage that allows all kinds of analysis and actions. For example, marketing data can be combined with sales and shipping data to generate a comprehensive report. Also, data from legacy systems can be combined with data from current systems to analyze customers lifetime interactions.
Several channels are provided for different actors to be able to exploit the information:
- Sigma
Sigma is a last generation SaaS tool designed for data exploration, visualization and analysis. It has the flexibility to provide a friendly interface for quick drafts and explorations, as well as a rich tool set to create professional looking corporate dashboards.During this project we created a set of dashboards that can be consulted by executives without any technical knowledge. Also there is the possibility for data analyst with some experience to create new dashboards or simply perform ad-hoc analysis and explorations - SQL Client
For technical people Sigma might be a bit limited if they want to perform complex queries and analysis. Because of that the data lake allows to connect using any SQL client (e.g. DBeaver) and take advantage of the powerful Redshift Cluster using SQL code - Sagemaker
This is an AWS service specifically designed to create, test and deploy Machine Learning models. Data scientists can connect this tool to the data lake and create advanced analytics models.
Lessons Learned
- Before any advanced analytics endeavor can be executed, a robust and reliable data infrastructure must be in place to support it
- Never underestimate the organizational challenges involved in a complex project. Sometimes they can be harder to tackle than the technical challenges themselves
- Data quality is paramount. Any data project will inexorably come across unreliable/corrupted/erroneous data. This must be anticipated and mechanisms put in place to address it minimizing the impact in the product
- Every step along the project, from high level design to implementation and modifications has to be carried out with the client’s input in mind. This is the only way that the final product delivers value to the business
- Documentation is key. Both during the project development (as an organizing force) as well as after the project for maintenance and onboarding of new team members
Key points
- We designed and implemented a cloud data lake based on the client urgent need for consistent data from their business
- We built a layered architecture to maintain a logical structure along the different data pipelines, making it robust and scalable
- For every data source ingested it was necessary a close coordination between the implementation team, the client and any third party involved
- We leveraged modern cloud tools to accomplish the task in the most efficient way possible: AWS services for storage and processing, dbt for data transformations, sigma for analysis and visualization
- The data lake has the flexibility to accommodate the needs from different business stakeholders, from executive monitoring high level metrics to data scientist performing complex queries and training machine learning models
- The resulting product is a single source of truth, with consistent and reliable data providing from several systems that can grow according to business requirements
Contact us today for a FREE Discovery Call, to learn how we can help you with your next project.
Email: info@fessexdev.wpengine.com